Back-pressure is an important feedback mechanism that allows systems to gracefully respond to load rather than collapse under it. The back-pressure may cascade all the way up to the user, at which point responsiveness may degrade, but this mechanism will ensure that the system is resilient under load.
Back-Pressure
This is how it’s defined in Reactive Manifesto:
Back-Pressure
When one component is struggling to keep-up, the system as a whole needs to respond in a sensible way. It is unacceptable for the component under stress to fail catastrophically or to drop messages in an uncontrolled fashion. Since it can’t cope and it can’t fail it should communicate the fact that it is under stress to upstream components and so get them to reduce the load. This back-pressure is an important feedback mechanism that allows systems to gracefully respond to load rather than collapse under it. The back-pressure may cascade all the way up to the user, at which point responsiveness may degrade, but this mechanism will ensure that the system is resilient under load, and will provide information that may allow the system itself to apply other resources to help distribute the load.
Let’s illustrate the context, that requires to apply back-pressure.
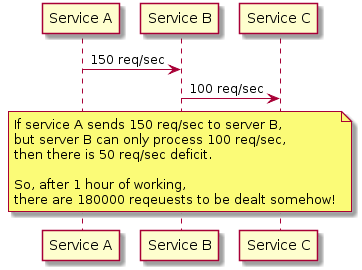
So, essentially the problem here is the mismatch in throughput between services.
Strategies to deal with throughput mismatch
There are several strategies to deal with throughput mismatch:
Auto-scale service, that is under pressure
Drop down (or sample) incoming requests, once service under pressure is saturated
Buffer requests
Control the request producer
Auto-scaling
Probably, auto-scaling is the easiest way to deal with the problem. E.g. in the example above the solution would be to scale the service B up - this definitely will resolve throughput deficit. In some cases this will be just enough, but in other - auto-scaling might lead to propagating the problem to the next service (e.g. service C). Also, if you are in severe cost/hardware deficit, scaling up is simply not feasible.
Dropping down or sampling
Only some fraction of incoming requests is processed, other are simply ignored. E.g. in the example above to solve the problem it would be enough for service B to just skip processing every 3rd request. However, most often it’s not applicable in practice
Buffering requests
Probably, applying buffer is the most intuitive thing to do. E.g. in the example above this approach can be implemented by introducing messaging queue between service A and B or, alternatively, storing incoming request to the database. This, in essence, allows service B to pull requests from buffer, when it’s ready to process them. However, beside the complication in infrastructure it’s not always possible, since not all requests might be processed asynchronously.
Controlling the request producer
Controlling the request producer is, actually, defined as"back-pressure" by Reactive Manifesto. In the example above it means, that service B should be able to slow down/speed up service A. So, service A should not push requests to service B, instead service B should pull desired number of requests from service A. However, controlling producer speed is not always an option (imaging telling your user to slow down). Also, back-pressure mechanism introduces complexity in the system, so should be decided carefully.
Conclusion
Whenever there is a mismatch in throughput between services there might be the opportunity to apply back-pressure pattern.
What strategy should be applied really depends on the constraints and requirements at hand.