Database Transaction represents a unit of work, that is atomic, consistent, isolated and durable (a.k.a. ACID).
Database Transaction
ACID guarantees are provided by traditional relational database management systems (RDBMS).
Atomicitymeans that operations, that constitute transaction are all either succeed or fail together. So, atomicity implies that there can’t be situation, in which part of operations succeeded and part failed.Consistencymeans that transaction leaves database in consistent state after execution. So, in practical terms, any data written to database must be valid according to integrity constraints (primary key/foreign key/unique key/etc.), cascades, triggers, and any combination thereof.Isolationdetermines how operations performed in a transaction are visible to other executing transactions. So, for example, whether data written by transaction is available for read by other concurrent transactions.Durabilitymeans that after transaction is committed, database changes are saved permanently. So, if database crushes all committed transactions will be restored. This is most often implemented by using transaction log stored in non-volatile storage. And transaction is committed only after it is entered in the log.
Transaction states
During execution database transaction goes through number of states:
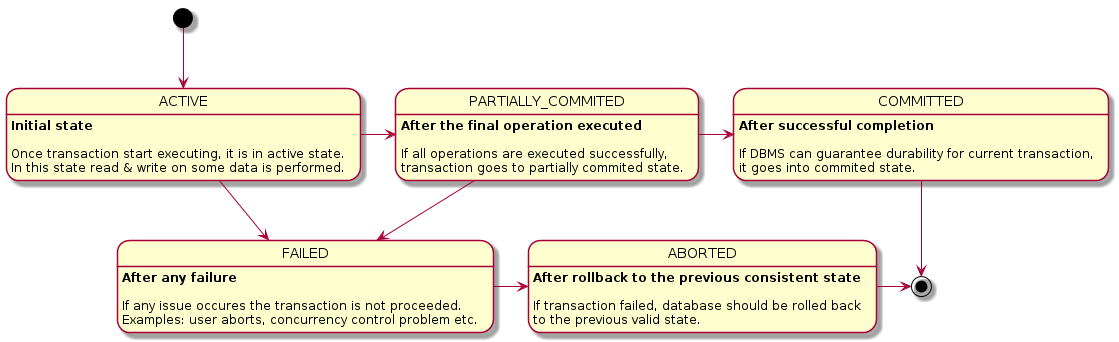
State transitions example
Assume we have two accounts: one for Alice (account A) and one for Bob (account B). Initially each account has 1000$ balance. The task is to transfer 100$ from account A to account B.
Database transaction for above situation can be represented as follows (in PostgreSQL syntax):
BEGIN;
UPDATE accounts SET balance = balance - 100.00
WHERE name = 'Alice'; (1)
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Bob'; (2)
COMMIT;Let’s follow state transitioning for this transaction:
In
ACTIVEstate read/write operations on database are performed. So, any statements betweenBEGINandCOMMITinstructions formACTIVEstate.If transaction reaches
COMMITwithout failures, then it goes intoPARTIALLY COMMITTEDstate. InPARTIALLY COMMITTEDstate, balances will have values: A = 900 and B = 1100.If the transaction executes
COMMITsuccessfully, that is, if it successfully writes the new value of A and B into log file or stable storage, then the transaction is said to be inCOMMITTEDstate.Transaction may enter
FAILEDstate:In
ACTIVEstate:before first
UPDATEended : then A = 1000 and B = 1000after first
UPDATEended: then A = 900 and B = 1100before
COMMITand after secondUPDATE: then A = 900 and B = 1100
In
PARTIALLY COMMITTEDstate: then A = 900 and B = 1100
The transaction enters
ABORTEDafter rollback. In this state DBMS has to undo the changes made so far. So, whatever balances are at the beginning inABORTEDstate, after roll back, the state will be reverted to the previous consistent state (A = 1000 and B = 1000)After entering
COMMITTEDorABORTEDstate, transaction is terminated
Why transaction may fail ? Database transaction might fail due to one or more of the following reasons:
DBMS usually can recover from server failure, logical failure or concurrency failure. To deal with disk failures - disk backups needs to be maintained. |
Savepoints
It’s possible to control the statements in a transaction in a more granular fashion through the use of savepoints. Savepoints allow you to selectively discard parts of the transaction, while committing the rest. After defining a savepoint with SAVEPOINT, you can if needed roll back to the savepoint with ROLLBACK TO. All the transaction’s database changes between defining the savepoint and rolling back to it are discarded, but changes earlier than the savepoint are kept.
After rolling back to a savepoint, it continues to be defined, so you can roll back to it several times. Conversely, if you are sure you won’t need to roll back to a particular savepoint again, it can be released, so the system can free some resources. Keep in mind that either releasing or rolling back to a savepoint will automatically release all savepoints that were defined after it.
Suppose we debit $100.00 from Alice’s account, and credit Bob’s account, only to find later that we should have credited Wally’s account. We could do it using savepoints like this:
BEGIN;
UPDATE accounts SET balance = balance - 100.00
WHERE name = 'Alice';
SAVEPOINT my_savepoint;
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Bob';
-- oops ... forget that and use Wally's account
ROLLBACK TO my_savepoint;
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Wally';
COMMIT;This example is, of course, oversimplified, but there’s a lot of control to be had over a transaction block through the use of savepoints.
Conclusion
Even though this post may seem pretty dry, however, it lays good foundation to get started working with transactions in your Data Access Layer.
In the next posts I will comeback to this topic from more practical perspective in the context of our lovely Spring Boot services. So, stay tuned ;)
References
You may also like

Lost Update Phenomena
An update is lost when a user overrides the current database state without realizing, that someone else changed it between the moment of data loading and the moment the update occurs. In this post,...